
This is a summary of the following research paper that we presented and published at the eCrime 2024 conference organized by APWG.
[1] Jehyun Lee, Peiyuan Lim, Bryan Hooi, and Dinil Mon Divakaran, “Multimodal Large Language Models for Phishing Webpage Detection and Identification,” in eCrime (Symposium on Electronic Crime Research), 2024.
Introduction
This research paper explores the efficacy of multimodal Large Language Models (LLMs) in detecting phishing webpages. The research aims to study how LLMs perform in identifying phishing targets, providing explanations, and handling different input types. It also investigates the robustness of an LLM-based solution against adversarial attacks and discusses new attack vectors.
Challenges faced by existing phishing detection methods: Existing phishing detection solutions suffer from several limitations that hinder their effectiveness. Blacklist-based approaches, which rely on identifying known phishing websites, are ineffective against newly created phishing pages. These lists require constant updates to keep pace with attackers' tactics, making them a reactive rather than proactive defense mechanism. Machine learning (ML) models, trained to distinguish between benign and phishing websites, encounter challenges due to increasing attack sophistication. Phishing pages often mimic legitimate sites closely, using similar resources and layout, making it difficult for ML models to accurately differentiate and classify them. This mimicry further exacerbates the problem, as the similarities between phishing and legitimate pages serve the attacker's goal of deceiving victims.
Brand-based phishing detection [2][3] leverages computer vision to identify imitated brands, often by comparing the visual representation (e.g., screenshot) of any given webpage to webpages of well-known targets (e.g., PayPal, Amazon, Facebook, top banking firms, etc.). While being effective, brand-based phishing detectors also have shortcomings. These solutions rely on large, labeled datasets for training, retraining, and maintaining a comprehensive reference list of targeted brands, a laborious and costly process. Additionally, the dynamic nature of phishing attacks, with brand names and their web representations evolving over time, makes maintaining an updated reference list challenging. Factors such as brand name changes, aliases, sub-brands, and regional variations further complicate domain verification, highlighting the limitations of statically defined brand and domain mappings.
The rise of LLMs presents new opportunity to tackle this challenging problem. In this study [1], we propose a two-phase system using LLMs to address these challenges:
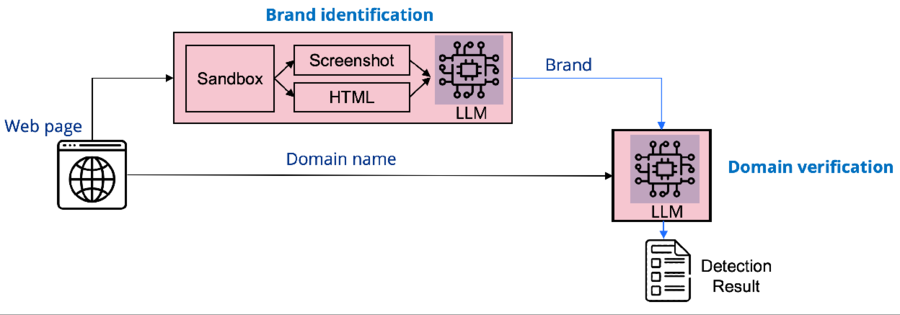
Figure 1: LLM-based system for detecting phishing webpages
Phase 1: Brand identification. This phase uses a multimodal LLM to identify the brand of a given webpage using its visual features (screenshot) and textual information (extracted from HTML content). The LLM is prompted to identify the brand, note credential-soliciting fields and call-to- action buttons, and provide supporting evidence for its decisions.
Phase 2: Domain verification. The system employs another LLM to compare the identified brand with the domain name in the URL. The LLM verifies whether the domain name matches the identified brand, considering factors like brand name changes, aliases, and regional variations. This process ensures a more robust and accurate phishing detection mechanism.
Advantages of an LLM-based solution
The proposed LLM-based phishing detection system offers several key advantages over existing solutions:
It leverages the vast knowledge and capabilities of multimodal LLMs, trained on massive datasets, including websites. This allows the system to analyze multiple aspects of a webpage, such as logos, themes, favicons, and textual content, to identify the brand. This approach surpasses the limitations of vision-based solutions that rely heavily on large, labeled datasets.
It employs a two-phase approach, combining brand identification with domain verification, to ensure robust detection. The first-phase LLM identifies the brand based on visual and textual features, while the second-phase LLM performs a comparison between the identified brand and the domain name, considering factors like brand name changes, aliases, and regional variations. This two-phase system enhances accuracy and reduces the reliance on statically maintained brand-domain mappings.
It provides interpretable results and supporting evidence for its decisions, enhancing transparency and user understanding. Unlike traditional ML models that often function as "black boxes," the LLMs can be queried to provide insights into their reasoning process, allowing users to understand the basis for phishing classification. This interpretability is valuable for security analysts and users who need to understand why a particular webpage is flagged as suspicious.
The proposed system offers flexibility in handling different input types, including both screenshot and HTML contents. While combining both inputs generally yields the best performance, the system can adapt to scenarios where only one type of data is available, such as using only screenshots to control costs associated with token consumption.
These advantages highlight the potential of the proposed LLM-based solution to address the limitations of existing phishing detection methods and provide a more robust and adaptable defense mechanism against phishing attacks.
Performance evaluations
We collected a new phishing dataset for the evaluations, addressing challenges such as cloaking tactics employed by phishing websites. We evaluate three state-of-the-art multimodal LLMs, namely GPT-4, Gemini Pro 1.0, and Claude3, on their capability to assist with phishing detection. Below are the key findings:
Key findings:
High phishing detection accuracy. GPT-4 and Claude3 demonstrated high precision and recall rates, thereby achieving high F1-scores, when provided with both screenshot and HTML content. While both input types of screenshot and HTML help in achieving high detection rate, Claude could achieve promising results with just webpage screenshot; this also helps in reducing cost (in terms of number of tokens utilized while querying an LLM.
Superior performance compared to VisualPhishNet [4] . The LLM-based system significantly outperformed VisualPhishNet, a state-of-the-art vision-based phishing detection system, demonstrating the capability of LLMs to analyze multiple aspects of a webpage.
Interpretable results. The LLMs provide explanations for their brand identification and phishing classification decisions, enhancing transparency and user understanding. Here is an example from the paper:

Figure 2: Explanation provided for the result - in this case, a phishing targeting WhatsApp
Robustness against adversarial attacks. The LLM-based system demonstrates robustness against two types of adversarial attacks studied in the literature: webpage source perturbation and noise perturbation on logos.
Value of domain verification. The second-phase LLM significantly improved detection performance, particularly for recall. For instance, Claude's F1-score increased by ~19% with the inclusion of domain verification.
New challenges
In the paper, we also discuss new challenges due to the use of LLMs in anti-phishing solutioning. These include new adversarial phishing attacks as LLMs are accessible to attackers as well, economic denial-of-service attack to maximize LLM API token usage, indirect prompt injection that manipulates LLM output to evade phishing detection, exploiting missing/obsolete information in LLMs, and poising data used for training LLMs.
References:
[1] Jehyun Lee, Peiyuan Lim, Bryan Hooi, and Dinil Mon Divakaran, “Multimodal Large Language Models for Phishing Webpage Detection and Identification,” in eCrime (Symposium on Electronic Crime Research), 2024.
[2] Y. Lin, R. Liu, D. M. Divakaran, J. Y. Ng, ?. Z. Chan, Y. Lu, Y. Si, F. Zhang, and J. S. Dong, “Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages,” in Proc. USENIX Security Symposium, 2021.
[3] R. Liu, Y. Lin, X. Yang, S. H. Ng, D. M. Divakaran, and J. S. Dong, “Inferring Phishing Intention via Webpage Appearance and Dynamics: A Deep Vision Based Approach,” in Proc. USENIX Security Symposium, 2022, pp. 1633–1650.
[4] S. Abdelnabi, K. Krombholz, and M. Fritz, “Visualphishnet: Zero-day phishing website detection by visual similarity,” in Proc. ACM CCS, 2020, pp. 1681–1698.


New Executive Order on Cybercrime and Fraud Marks a More Coordinated U.S. Response
A U.S. Executive Order targets cybercrime, scams, and global fraud networks with a more coordinated government response.

Global Anti-Scam Alliance Launches Scam.org with OpenAI and Key Partners
The Global Anti-Scam Alliance (GASA) launched today Scam.org, an AI-powered platform that provides scam education, prevention, detection, reporting, and victim support.

La Industrialización del Engaño: Por qué 2026 será el año en que las estafas cibernéticas cambien para siempre
El auge de la inteligencia artificial está eliminando las señales tradicionales de alerta y transformando las estafas en un sistema industrial a gran escala.

The Industrialization of Deception: Why 2026 Will Be the Year Cyber Scams Change Forever
The rise of artificial intelligence is eliminating traditional warning signs and transforming scams into a large-scale industrial system.
What to Expect From Scams in 2026 in the Age of AI
Experts discuss how AI is changing scam tactics and what to expect in 2026, in this webinar hosted by GASA Brazil.

Global Anti-Scam Alliance Policy Agenda 2026
The Global Anti-Scam Alliance outlines its 2026 policy agenda, setting priorities across consumer education, intelligence sharing, prevention, enforcement, research and financial disruption.

GASA Mexico Convenes First National Roundtable and Signs MOU With Cybersecurity Directorate, Setting Ambitious Agenda for Cross-Sector Collaboration to Fight Digital Scams & Fraud
GASA Mexico convened its first national roundtable and signed an MOU with Mexico’s Government Cybersecurity Directorate to strengthen coordinated action against scams and digital fraud.

GASA Launches Africa Chapter to Strengthen Regional Scam Prevention
GASA is launching its Africa Chapter, creating a dedicated platform for public and private sector collaboration across the continent.